谢谢各位大佬的回答!我是业余爱好者,主业是做医药的。
最早开始接触编程是给 Obsidian 写插件,学了一些些 TypeScript 和 Vue 3 ,也就基本够用的水平。Rust 学到了多线程,后面感觉很难还没敢继续深入学习…… 不过学着学着突然就冒出了很多以前我没听说过的新语言,也不知道学哪个好,故才问此问题。
我其实是想写一些跨平台的研究工具(带 GUI 的),涉及科学计算所以要求计算结果比较精确。Electron 可以吗(这个框架好像很火啊,新版 QQ 好像也是用的这个)?还是 Tauri 比较好?Python 是不是也可以开发 GUI 程序啊不过会不会性能不太好?或者大佬还有没有其它的推荐呢  ?
?
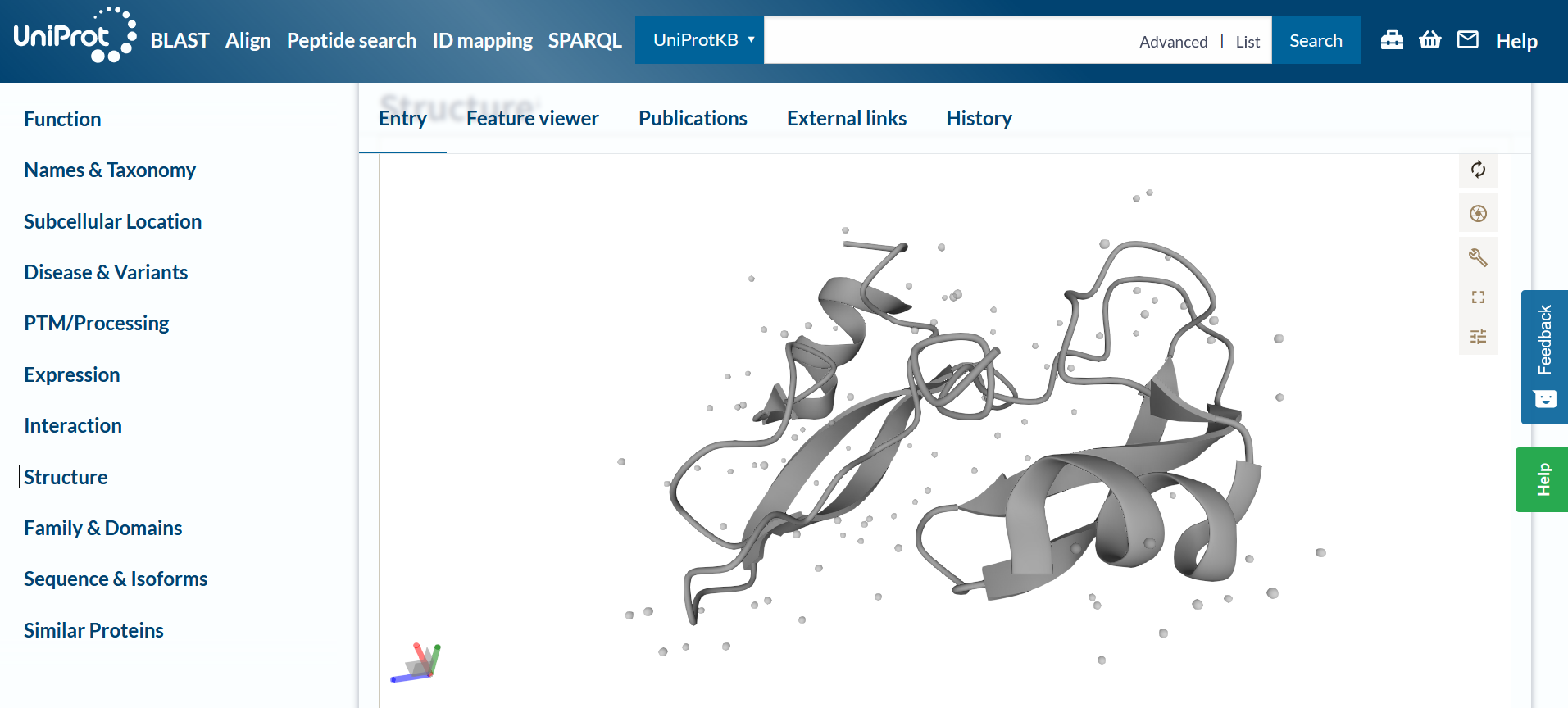
还有我有一个非常好奇的问题,就是像这些网页里的 3D引擎 到底是怎么做出来的  ?!一个人的话有机会开发出来吗?
?!一个人的话有机会开发出来吗?